F37.101 컴퓨팅 기초: 처음 만나는 컴퓨팅(First Adventures in Computing)
Chapter 9. 데이터과학의 이해#
학습목표와 기대효과
학습목표
데이터 과학을 이해하고 활용 분야를 생각해보자.
데이터 분석의 절차를 알아보자.
데이터 분석을 위한 스토리텔링을 해보자.
데이터 분석 핵심 모듈 4종 세트를 맛보자.
기대효과
데이터 분석의 기본 절차를 이해하고, 간단한 스토리텔링을 실습해 볼 수 있다.
주요 모듈(Numpy, Pandas, Matplotlib, Seaborn)의 특징과 서로 간의 연결 과정을 확인할 수 있다.
데이터 과학의 이해#
데이터 과학 분야는 문제 해결을 위해 데이터를 준비하고, 분석하고, 적용하는 방법을 다루는 분야이다.
데이터 수집과 분석은 통계학, 컴퓨터과학, 경영학, 경제학, 사회학, 생물학 등 오래 전부터 여러 분야에서 수행되어 왔다.
그러나 이전의 데이터과학 분야에서의 과학적 탐구 방식은 원인을 알아내는데 치중했다. 예를 들어, 왜 경제가 어려운지, 왜 바람이 서쪽에서 부는지, 왜 특정 바이러스가 병을 일으키는지 등 현상이 일어난 원인을 알아내고, 이를 설명할 수 있는 원리와 이론을 발견하는 방향으로 다루어졌다.
지금의 데이터 과학은 답을 얻을 수 있는 상관관계를 알아내는 것에 더 가치를 둔다.
예를 들어, ‘어떤 특이한 현상이 발생하면 한달 내에 불경기가 온다.’, ‘어떤 키워드를 사람들이 많이 검색하면 그 지역에서 독감이 유행한다.’ 등 분석을 통해 현상에 대한 원인관계를 확인하는 것에 치중한다.
하나의 예로, “허리케인이 오면 비상식량으로 생수가 많이 팔린다.”, “허리케인이 오면 손전등과 비상 장비가 많이 팔린다.” 이와 같은 현상은 예상 가능한 결과였다. 그런데, Walmart의 데이터 분석을 통한 수요 예측에 따르면, “허리케인이 오면 탄산음료 판매가 급격하게 상승한다”는 의외의 결과가 나왔다.
그 상관관계를 확인해 본 결과, 비상식량 중에는 마른 식품이 많고, 마른 식품은 갈증을 유발하게 되어 탄산음료 판매가 증가하였던 것이다.
이와 같이 지금의 데이터 과학은 허리케인과 탄산음료의 상관관계를 알고, 이후 분석에서 원인관계를 확인하는 방향에 더 가치를 두고 있다.
데이터 과학은 사건 발생의 정확한 원인은 밝히지 못하더라도 미래를 예측할 수 있는 방법을 찾아내거나 의사결정에도 많은 도움을 준다.
데이터 과학의 활용#
데이터 과학은 기업마케팅, 범죄예방, 의료분야, 교통분야 등 실제 다양한 분야에서 활용되어지고 있다.
기업마케팅#
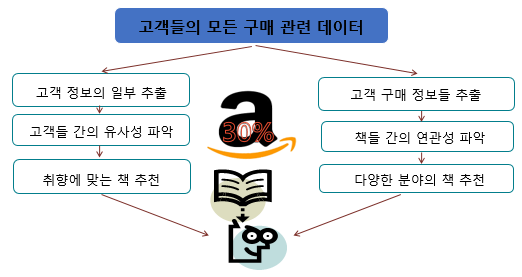
기업에서는 고객 들의 구매 관련 데이터를 수집해 놓았다가 고객 정보의 일부를 추출하여 고객들간의 유사성을 파악하고 취향에 맞는 책을 추천해 주는데 데이터 과학을 활용한다.
또한 고객 구매 정보들을 추출하여 책들 간의 연관성을 파악하고 연관성 있는 분야의 책을 추천해 주기도 한다.
범죄예방#

2002년에 개봉한 탐크루즈 주연의 ‘마이너리티리포트’라는 범죄예방 영화가 있다. 이 영화에서는 2054년 워싱턴를 배경으로 프리크라임이라는 최첨단 치안 시스템이 범죄가 일어날 시간과 장소, 범행을 저지를 사람까지 미리 예측해내고 범죄가 일어나기 전 특수 경찰들이 미래의 범죄자들을 체포한다는 내용이다. 아직 범죄를 저지르지 않았는데 체포한다는 것이 말이 될까 싶다.
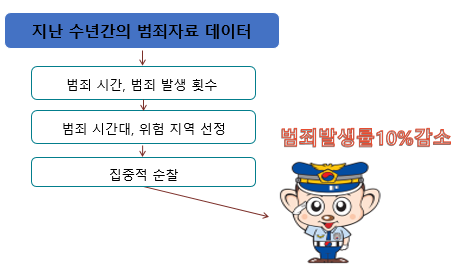
어쨌든, 데이터과학은 범죄예방에도 사용된다. 지난 수십년간의 범죄자료 데이터를 수집해 놓았다가 범죄시간, 범죄 발생 횟수 등을 토대로 범죄가 일어날 것 같은 시간대, 위험 지역을 선정하는데 데이터 과학을 활용한다.
이와 같이 데이터 분석을 토대로 위험지역에 대해 집중적 순찰을 한 결과 범죄 발생률을 감소 시킬 수 있었다고 한다.
의료분야#

구글 독감 트렌드(GFT: Google Flu Trends)는 빅데이터의 성공 사례로 곧잘 언급되는 내용이다.
구글은 미국 질병관리본부(CDC)가 공개한 2003년부터 2007년까지의 독감 데이터(독감 증상으로 병원을 방문한 환자의 수)와 동일한 시기에 구글 사용자가 입력한 검색어와의 상관관계를 분석하였다.
이를 분석하여 과거 독감 데이터와 높은 상관관계를 보이는 사용자의 검색어 45개(고열, 기침 등)를 사용해 질병관리본부보다 2주 빨리 독감 유행을 예측할 수 있는 모형을 개발하는데 데이터과학을 활용하였다.
교통분야#

데이터 과학은 교통분야에서도 요긴하게 사용될 수 있다. 사람들의 휴대폰 사용 기록을 토대로 어느 시각, 어느 지역에서 가장 많이 사용하는지를 조사한 후, 이를 기반으로 새로운 노선을 결정하거나, 노선을 확대하는 등의 결정에 사용되기도 한다.
데이터 분석 절차#
데이터 분석 절차는 데이터 분석을 통해 문제를 해결하는 과정을 일컫는다.
다음과 같이 5단계로 정의할 수 있다.

문제 정의#
해결하려는 문제를 명확히 정의하는 단계이다.
큰 문제는 한번에 해결하기 어려우므로, 해결 가능한 크기의 작은 문제로 나누어 접근하는 전략이 필요하다.
작은 문제로 나눌 때에는 분석 방법이 널리 알려진 문제 단위로 나눈다.
전략 수립#
문제해결을 위해 어떤 데이터를 어떻게 분석할지 결정하는 단계이다.
문제의 본질을 파악하고 문제 해결 목표를 명확히 정해야 한다. 예를 들어, 비용 20% 줄이기, 문제 영역 3곳 찾기 등
전략을 수립하면서 확인해야 할 사항으로는 데이터 수집 비용, 마감일, 최소한의 성능 요건, 가용 자원(인적자원, 사용 데이터 수), 전산 자원, 데이터 분석방법, 데이터 분석에 소요되는 비용 등을 확인해야 한다.
데이터 수집(수집, 정제, 집계)#
분석에 필요한 데이터를 수집하는 단계이다.
목적을 정하고 데이터를 수집하는 것이 일반적이며, 이상적인 절차이다.
데이터 수집은 많은 비용과 시간이 필요한 단계이며, 일반적으로 전체 과정의 70~80%는 데이터를 모으고 준비하는데 소요된다.
데이터를 수집하면서 수집한 데이터 전체 모습 및 데이터 자체에 문제가 있는지 확인이 필요하다.
데이터 분석#
패턴 찾기, 분류, 예측 등 분석 모델 구현하는 단계이다.
데이터 분석 유형으로는 기초 통계 분석(평균, 분산 등 데이터 분포 파악), 클러스터링(유사 항목 묶음), 연관관계 분석, 분류(정해진 카테고리에서 판별), 예측(주가, 매출 등 수치 예상) 등이 있다.
결과 적용#
분석 결과를 실제 상황에 적용하고 성능을 개선하는 단계이다.
실제로 어떻게 적용할지 미리 시뮬레이션을 해 보는게 필요하다.
분석 결과를 쉽게 이해시키기기 위해 시각화(visualization) 필요하다.
데이터 스토리텔링#
문제정의
각 구별 CCTV의 수는 인구수 대비 적절한가?
CCTV 수가 많은 지역과 적은 지역은 어디인가?
관련된 자료의 수집
필요한 데이터 정의: 서울시 구별 인구 데이터와 CCTV수 데이터
어디서 수집할 것인가: 공공데이터로부터 획득
서울시 CCTV 현황 데이터 구하기: 공공데이터 포털: https://www.data.go.kr/
서울시 인구 현황 데이터 구하기 : 서울 열린데이터 광장: https://data.seoul.go.kr/
수집한 자료의 가공, 정제, 필터링, 정렬 등
구별 인구 데이터와 CCTV수 데이터 합치기
데이터 분석
통계 등을 사용한 요약 테이블 작성
구별 인구 데이터와 CCTV수 사이의 상관관계 구하기
자료 시각화
구별 인구 데이터와 CCTV수 사이의 관계를 나타내는 대표직선 구하기
대표직선으로부터의 오차 구하기
인구 데이터와 CCTV수를 산포도로 표현 + 산포도 marker색을 오차로 표현
대표직선을 선형 그래프로 표현
오차가 큰 상위 10개구의 구 이름 표시
문제 정의에 대한 결론
이 문제는 pandas, numpy, matplotlib, seaborn을 배운 후 종합예제로 다룰 것이다.
필요한 핵심 모듈 4종 세트 맛보기#
구분 |
Numpy |
Pandas |
Matplotlib |
Seaborn |
|---|---|---|---|---|
한 줄 정의 |
수치 계산을 위한 배열(행렬) 라이브러리 |
표 형태(엑셀 같은) 데이터 분석 도구 |
기본 그래프를 그리는 시각화 도구 |
예쁘고 간결한 시각화 도구 |
주요 기능 |
- 빠른 수치 계산 |
- CSV/엑셀 불러오기 |
- 선, 막대, 원형 그래프 등 기본 시각화 제공 |
- Matplotlib 기반 고급 그래프 |
데이터 형태 |
|
|
수치나 표 기반 그래프 |
Pandas DataFrame 기반 그래프 |
코드 예시 |
|
|
|
|
필요 모듈 |
|
|
|
|
사용 목적 |
수학적 처리 |
데이터 관리와 분석 |
데이터 시각화 |
시각적 인사이트 전달 |
한 문장 요약 |
“데이터의 숫자를 계산한다” |
“데이터를 표로 다룬다” |
“데이터를 그림으로 그린다” |
“그림을 예쁘고 쉽게 만든다” |
?? 엑셀로도 분석이 가능한데, 왜 굳이 Python을 쓸까요??
많은 데이터, 반복 자동화, 코드 재활용의 가능성을 열어둬야 한다.
numpy 예시#
import numpy as np
# 학생 10명의 키 데이터 (단위: cm)
heights = np.array([160, 165, 170, 172, 168, 174, 169, 171, 166, 173])
# 평균, 표준편차, 최댓값, 최솟값 계산
mean_height = np.mean(heights)
std_height = np.std(heights)
max_height = np.max(heights)
min_height = np.min(heights)
print("평균 키:", mean_height)
print("표준편차:", std_height)
print("가장 큰 키:", max_height)
print("가장 작은 키:", min_height)
# 키를 cm → m 단위로 변환
heights_m = heights / 100
print("미터 단위 변환:", heights_m)
평균 키: 168.8
표준편차: 4.019950248448356
가장 큰 키: 174
가장 작은 키: 160
미터 단위 변환: [1.6 1.65 1.7 1.72 1.68 1.74 1.69 1.71 1.66 1.73]
pandas 예시#
import pandas as pd
data = {
'Menu': ['Americano', 'Latte', 'Cappuccino'],
'Sales': [45, 30, 25],
'Price': [4000, 4500, 5000]
}
df = pd.DataFrame(data)
print(df)
print("Average sales:", df['Sales'].mean())
Menu Sales Price
0 Americano 45 4000
1 Latte 30 4500
2 Cappuccino 25 5000
Average sales: 33.333333333333336
시각화 예시#
import matplotlib.pyplot as plt
# Create histogram
plt.figure(figsize=(6, 4))
plt.hist(heights, bins=5, color='skyblue', edgecolor='black')
# Add mean line
plt.axvline(mean_height, color='red', linestyle='--', label=f'Mean: {mean_height:.1f} cm')
# Add title and labels
plt.title('Height Distribution of Students', fontsize=14)
plt.xlabel('Height (cm)')
plt.ylabel('Number of Students')
plt.legend()
plt.grid(alpha=0.3)
plt.show()
<Figure size 600x400 with 1 Axes>
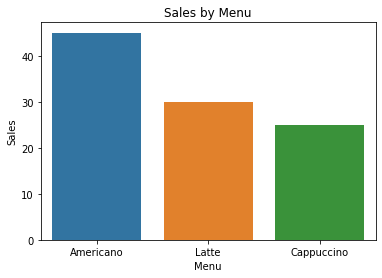
import matplotlib.pyplot as plt
import seaborn as sns
sns.barplot(x='Menu', y='Sales', data=df)
plt.title('Sales by Menu')
plt.xlabel('Menu')
plt.ylabel('Sales')
plt.show()
D:\users\anaconda3\lib\site-packages\statsmodels\tools\_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
나만의 질문으로 시작하는 데이터 분석#
아래 데이터셋을 선택하고, 직접 분석 질문을 최소 5개 이상 도출해 봅시다.
1. 데이터 불러오기#
분석에 사용할 수 있는 다양한 데이터셋이 아래에 제공되어 있습니다. 링크를 누른후, 마우스 오른쪽 버튼을 눌러 “다른 이름으로 저장”으로 다운로드 하세요.
데이터셋 목록 - 일괄다운로드#
import pandas as pd
# 예시: Supermarket Sales 데이터 불러오기
df = pd.read_csv('파일경로 또는 URL')
df.head()
import pandas as pd
# 예시: complete.csv파일의 경우 bad line이 있어서 on_bad_lines옵션을 이용해서 bad line을 skip하도록 함
df = pd.read_csv('complete.csv', on_bad_lines='skip')
df.head()
import pandas as pd
# 예시: 엑셀파일의 경우
df = pd.read_excel('파일경로 또는 URL')
df.head()
2. 데이터 구조 파악하기#
데이터셋을 불러온 후, 전체 구조를 파악합니다.
df.info() #DataFrame의 전체 구조를 보여줌
df.describe() #DataFrame의 숫자형 컬럼들에 대해 통계를 보여줌
df.columns #DataFrame의 칼럼 이름을 보여줌
3. 분석할 질문 정하기#
데이터를 관찰한 후, 분석하고 싶은 질문을 최소 5개 이상 정해보세요.
예시:
어떤 항목이 가장 많은 매출을 차지하고 있을까?
특정 변수 간에 관계(상관관계)는 있을까?
시간이나 지역에 따른 변화 추세는 있는가?
성별/국가/등급 등 그룹에 따른 차이는 존재하는가?
질문 1: _________________________________________
질문 2: _________________________________________
질문 3: _________________________________________
질문 4: _________________________________________
질문 5: _________________________________________
마무리#
데이터 과학이란 정형, 비정형 데이터로부터 지식과 인사이트를 추출하는데 과학적 방법론, 프로세스, 알고리즘 및 시스템을 이용하여 데이터에서 가치를 도출하는 통합 학문이다.
데이터 분석을 통해 미래를 예측할 수 있는 방법을 찾아내거나 의사결정에 도움을 준다.
데이터 분석의 절차는 문제정의 -> 전략수립 -> 데이터 수집 -> 데이터분석 -> 결과적용으로 진행된다.
F37.101 컴퓨팅 기초: 처음 만나는 컴퓨팅(First Adventures in Computing) 서울대학교 학부대학 변해선