Chapter 9-1. 웹과 웹크롤링#
학습목표와 기대효과
학습목표
웹페이지의 구성과 동작을 이해한다.
웹크롤링(web crawling)과 웹스크래핑(web scraping)의 개념을 알아보자.
urlopen() 함수로 웹크롤링을 해보자.
BeautifulSoup() 함수로 웹스크랩핑을 해보자.
기대효과
웹페이지가 어떠한 방법으로 만들어지고 동작되는지 이해할 수 있다.
웹에서 데이터를 수집할 수 있다.
웹(www)과 HTML#
웹주소를 보면 보통 시작이 www이다. www는 world wide web의 약자로 web이 거미줄이라는 뜻을 가지고 있어서 전 세계로 퍼진 거미줄로 직역할 수 있다. 웹에서 보여지는 페이지(문서)를 웹페이지라고 하며, 웹페이지를 만드는데 사용되는 언어중 하나가 바로 HTMLHTML(HyperText Markup Language)이다.
HTML은 Hypertext Markup Language의 약자로, 웹페이지가 어떻게 구조화되어 있는지를 웹브라우저(크롬, 익스플로러, 엣지, 사파리 등)가 인식하도록 하는 마크업 언어이다.
마크업(Markup)? 마크다운(Markdown)?
마크업 언어(Markup Language)란
태그등을 이용하여 문서가 화면에 표시되는 형식을 나타내거나 데이터의 논리적인 구조를 명시하기 위한 규칙들을 정의한 언어의 일종이다. 데이터를 기술한 언어라는 점에서 프로그래밍 언어와는 차이가 있다.마크다운 언어(Markdown Language)는 마크업 언어의 일종으로 마크업이 복잡한 태그로 구성되어 있어서 사용하기 힘들어서 만들어진 마크업의 파생형언어이다. 읽기도 쓰기도 쉬운 문서 양식을 지향하므로 복잡한 태그 구조가 사라지고 간단한 텍스트들과 몇 가지 문법만 알면 작성할 수 있다.
태그(tag)#
HTML로 작성된 페이지는 다양한 태그로 구성되어 있다.태그(tag)는 웹 상의 다른 페이지로 이동하게 하는 하이퍼링크를 생성하거나, 단어를 강조하는 등의 다양한 역할을 한다.
태그에는 여는(opening) 태그와 닫는(closing) 태그가 있다.
여는 태그와 닫는 태그 사이에는 내용(content)이 들어간다.
<여는 태그> 내용 </닫는 태그>
예를 들어, 아래에서 여는 태그는
<p>, 닫는 태그는</p>, 내용은아름다운 날이에요.가 된다.
<p>아름다운 날이에요.</p>
여는 태그, 닫는 태그, 내용을 통틀어 요소(element)라고 한다.
아래 매우 간단한 HTML문서를 살펴보자.
<!DOCTYPE html >
<html>
<head>
<title> This is my page </title>
</head>
<body>
<p>아름다운 날이에요.</p>
</body>
</html >
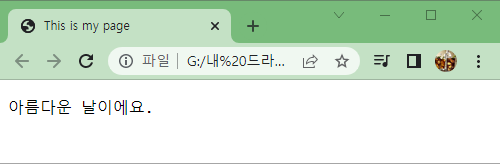
이 HTML문서를 웹브라우저에서 열면 HTML 코드가 9줄로 구성되었던 것과는 달리 아래와 같이
아름다운 날이에요.한 줄만 보여진다.
HTML문서안에 들어있는 태그를 하나 하나 파헤쳐보자.
HTML 문서는
<!DOCTYPE html>태그로 시작한다. 이 태그는 문서의 타입을 정의하는 태그로 이 페이지가 html로 구성된 문서임을 웹브라우저가 알게 한다.그 이후 여는 태그
<html>로 열고, 끝은 닫는 태그</html>로 닫는다.<html> ~ </html>는 전체 페이지의 컨텐츠를 포함하는 기본 요소이다.<html> ~ </html>태그 사이에는 크게<head> ~ </head>태그와<body> ~ </body>태그로 구성된다.<head> ~ </head>태그 안에는 웹페이지의 인코딩 방식, 웹페이지의 제목, CSS(Cascading Stylesheets)의 링크, 그 밖의 부가정보(작성자, 중요 키워드)를 포함한다. 그러나 이러한 정보들은 웹페이지의 제목을 제외하고는 웹 브라우저에 표시되지 않는다.<body>~</body>태그 안에는 텍스트, 이미지, 비디오, 게임, 재생 가능한 오디오 트랙 등을 비롯하여웹페이지에 표시되는 모든 콘텐츠가 들어간다.
태그 안에는 또 다른 태그가 중첩되기도 한다.
한 예로, 아래에서
<p> ~ </p>태그 사이에<strong> ~ </strong>태그가 중첩되어 있다. 참고로<p>태그는 paragraph를 의미하며,<strong>은 진하게 나타내라는 의미이다. (웹을 만드는 것이 목적이 아니므로 태그를 외우거나 의미가 무엇인지 알 필요가 없다.)
<p> 수강취소 안하고 여기까지 온 <strong> 당신 매우 멋지십니다.</strong> </p>
출력 결과는 아래와 같다.
수강취소 안하고 여기까지 온 당신 매우 멋지십니다.
또한, 일부 태그는 여는 태그만 있고, 닫는 태그가 없는 단일 태그(Single tag) 형태도 있다.
한 예로,
<img>태그는 이미지를 보여주기 위한 태그로 여는 태그만 있다.
<img src="https://haesunbyun.github.io/common/images/html2.png">
웹페이지에서 보여지는 결과는 다음과 같다.

속성(attribute)#
여는 태그안에는 하나 이상의
속성을 넣을 수 있다.속성은 요소에 추가적인 성질, 링크, 내용 등을 포함시키고 싶을 때 사용하며 실제 웹페이지에 보이지는 않는다.
속성을 주는 형식은 다음과 같다.
< 여는 태그 속성명="속성값" 속성명="속성값" ...>
태그와 속성, 속성과 속성 사이에는 공백이 있으며, 속성 값은 따옴표로 감싸져 있다.
<p class="editor-note"> 안녕하세요.</p>
<p> 여기는 <a href="https://www.snu.ac.kr/" title="서울대학교 홈페이지">서울대학교</a>입니다.</p>
img 태그의
srcp 태그의class, a 태그의href,title이 속성명이다."editor-note", "https://www.snu.ac.kr/", "서울대학교 홈페이지"는 속성 값이다.웹페이지에서 보여지는 결과는 아래와 같다. 속성이 많지만 웹페이지에서는 보이지 않는다.
안녕하세요.
여기는 서울대학교입니다.
웹 동작#
웹은 다음과 같이 동작한다.
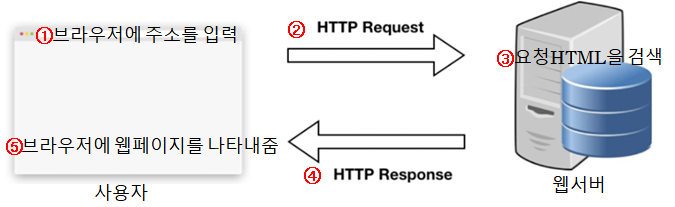
일반적으로 웹페이지에 접속하기 위해서는 웹브라우저의 주소입력창에 접속하고자 하는 URL((Uniform Resource Locator)을 입력한다.
URL이 입력되면 브라우저는 HTTP Request 메시지를 웹서버에게 보낸다.
여기서 HTTP는 HyperText Transfer Protocol의 약자로, 하이퍼미디어 문서를 전송하기 위한 프로토콜이다. 프로토콜이란 컴퓨터들 간 데이터 통신을 원활하게 하기 위해 필요한 통신 규약을 의미한다.
URL 앞에 http:// 또는 https:// 라고 쓰는 이유도 http 프로토콜이 사용된다는 뜻이다.
웹서버는 HTTP Request 메시지를 받으면 해당 웹문서가 웹서버에 있는지 검색하고 그에 대한 결과를 HTTP Response에 실어 보낸다. 웹문서가 있다면 그 컨텐츠도 함께 넣어 보낸다.
브라우저에서는 HTTP Response를 받아 웹문서를 브라우저에 나타낸다.
웹크롤링과 웹스크랩핑#
웹은 무한히 많은 데이터가 있는 정보의 바다이다. 이러한 웹에서 유의미한 데이터를 찾는 것은 매우 중요한 일이 됐다.
웹 페이지에서 정보를 추출하는 프로그램을 웹크롤러(Web Crawler), 또는 스파이더(Spider), 봇(Bot)이라고도 부르며, 크롤러를 사용하여 데이터를 수집하는 것을 크롤링(Crawling)이라고 하다.
즉, 웹크롤링은 웹페이지의 하이퍼링크를 순회하면서 웹 페이지를 다운로드 하는 작업을 의미한다.
웹스크랩핑(Scraping)은 다운로드한 웹 페이지에서 필요한 정보를 추출하는 작업을 의미한다.
일부 모듈들은 웹크롤링과 웹스크랩핑 기능을 모두 갖고 있기도 해서 이를 혼용하여 부르기도 한다.
웹크롤링은 다양하게 활용되고 있다.
음식점의 예약 상황을 실시간으로 추출하여 어떤 음식점에 자리가 비어있는지, 어떤 요일과 어떤 시간에 어떤 음식점이 인기 있는지 등의 정보를 추출하는데 활용되기도 한다.
여러 책 판매 사이트에서 정보를 추출하여 직접 가격 비교해서 최저가 정보를 알려주거나 웹사이트에서 정보를 추출하고 정보를 정리하는데 사용되기도 한다.
정부, 자치단체, 기업 등이 자유롭게 사용할 수 있도록 공개한 데이터인 열린 데이터를 수집할 때도 도움이 된다.
웹데이터 분석, 자연언어분석, 이미지 처리 등 대량의 데이터 수집이 필요 할 때도 이용된다.
파이썬 언어를 통해 크롤링을 하는 방법은
표준라이브러리인 urllib.request 모듈
사람들이 직접 만들어 공개한 라이브러리(서드파티:Third Party)인 requests 모듈, Selenium 모듈 등이 있다.
스크레이핑(Scraping) 하는 방법은
re모듈을 사용한 정규표현식으로 추출
요소를 지정하는 방식 Xpath와 CSS 선택자
BeautifulSoup 모듈
Selenium 모듈 등이 있다.
urlopen()으로 웹페이지 가져오기#
웹크롤링을 하기 위해서는 먼저 웹페이지에 접속부터 해야 한다.
파이썬으로 웹페이지에 접속하기 위해서는 urllib.request 모듈의 urlopen() 함수를 통해 할 수 있다.
urllib 패키지는 URL과 관련된 작업을 하기 위한 여러 모듈을 모은 패키지로, 그중에서 urllib.request 모듈은 URL을 여는것과 관련한 다양한 함수를 제공하고 있다.
먼저, urlopen() 함수를 import하고, urlopen() 괄호안에 접속할 사이트의 주소를 넣어준다.
아래 웹페이지를 가져와보자.
from urllib.request import urlopen
page = urlopen('https://haesunbyun.github.io/Basic-Computing/mypage3.html')
print(page)
<http.client.HTTPResponse object at 0x0000025B9CA7CBC8>
변수 page를 출력해보면, 에러없이 웹페이지를 열었지만 반환된 값은 웹문서 스타일이 아니라 HTTPResponse 객체이다.
BeautifulSoup()으로 웹스크랩핑하기#
urlopen()으로 가져온 웹페이지를 눈으로 확인 가능한 HTML문서로 바꿔보자.
이를 위해 BeautifulSoup() 함수를 활용할 수 있다.
BeautifulSoup() 함수는 HTML에서 데이터를 추출할 수 있도록 하는 함수로 HTML 구문 분석 기능을 갖고 있다.
먼저 bs4모듈에 BeautifulSoup() 함수를 import한다.
BeautifulSoup() 함수의 괄호안에는 첫 번째 전달인자로 구문을 분석하고자 하는 HTML, 두 번째 전달인자로 분석할 파서의 종류를 넣어준다. 여기서는 html 구문으로 파싱할 것이므로 ‘html.parser’로 적어준다.
파싱(parsing)이란 구문 분석이라는 뜻으로 각 구성 성분으로 분해하고 이들간의 관계를 분석하여 구조를 결정하는 작업을 말한다.
파싱하여 변수 soup에 저장하여 출력해보면 urlopen()으로 가져왔던 웹페이지가 html코드로 보여진다.
통상적으로 BeautifulSoup()으로 파싱한 객체는 변수 이름을 soup으로 한다.
from bs4 import BeautifulSoup
soup=BeautifulSoup(page,'html.parser')
print(soup)
<!DOCTYPE html>
<html>
<head>
<title>Very Simple HTML Code by Haesun</title>
</head>
<body>
<div class="tex2jax_ignore mathjax_ignore section" id="id1">
<h1>소개<a class="headerlink" href="#id1" title="Permalink to this headline">#</a></h1>
<p>L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅</p>
<p>프로그래밍 입문자와 비전공자를 위한 파이썬 프로그래밍 기초와 데이터 과학 기초를 다룬다.</p>
<p>컴퓨팅 기초: 처음 만나는 컴퓨팅 001,002,003 강좌 수강생들을 위한 자료이니 복제, 무단배포, 링크공유를 금합니다.</p>
<div class="toctree-wrapper compound">
<p aria-level="2" class="caption" role="heading"><span class="caption-text">Python</span></p>
<ul>
<li class="toctree-l1"><a class="reference internal" href="B_chapter0.html">Chapter 0. 프로그래밍 언어와 파이썬</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter1.html">Chapter 1. 기본자료형과 변수</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter2.html">Chapter 2. 입출력과 타입변환</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter3.html">Chapter 3. 조건문</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter4.html">Chapter 4. 반복문</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter5.html">Chapter 5. 리스트</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter6.html">Chapter 6. 함수</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter7.html">Chapter 7. 딕셔너리, 튜플, 셋</a></li>
</ul>
<p aria-level="2" class="caption" role="heading"><span class="caption-text">Web Crawing</span></p>
<ul>
<li class="toctree-l1"><a class="reference internal" href="B_chapter9.html">Chapter 9. 웹과 웹크롤링</a></li>
</ul>
<p aria-level="2" class="caption" role="heading"><span class="caption-text">Data Science</span></p>
</div>
</div>
</body></html>
HTML언어는 파이썬과 다르게 들여쓰기가 필요없는 언어이다.
그러나 들여쓰기가 되어 있으면 문서의 구조를 파악하는데 도움이 된다.
soup.prettify()는 들여쓰기를 적용해 문서의 구조를 보기 쉽게 바꿔주는 메서드이다.
print(soup.prettify())
<!DOCTYPE html>
<html>
<head>
<title>
Very Simple HTML Code by Haesun
</title>
</head>
<body>
<div class="tex2jax_ignore mathjax_ignore section" id="id1">
<h1>
소개
<a class="headerlink" href="#id1" title="Permalink to this headline">
#
</a>
</h1>
<p>
L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅
</p>
<p>
프로그래밍 입문자와 비전공자를 위한 파이썬 프로그래밍 기초와 데이터 과학 기초를 다룬다.
</p>
<p>
컴퓨팅 기초: 처음 만나는 컴퓨팅 001,002,003 강좌 수강생들을 위한 자료이니 복제, 무단배포, 링크공유를 금합니다.
</p>
<div class="toctree-wrapper compound">
<p aria-level="2" class="caption" role="heading">
<span class="caption-text">
Python
</span>
</p>
<ul>
<li class="toctree-l1">
<a class="reference internal" href="B_chapter0.html">
Chapter 0. 프로그래밍 언어와 파이썬
</a>
</li>
<li class="toctree-l1">
<a class="reference internal" href="B_chapter1.html">
Chapter 1. 기본자료형과 변수
</a>
</li>
<li class="toctree-l1">
<a class="reference internal" href="B_chapter2.html">
Chapter 2. 입출력과 타입변환
</a>
</li>
<li class="toctree-l1">
<a class="reference internal" href="B_chapter3.html">
Chapter 3. 조건문
</a>
</li>
<li class="toctree-l1">
<a class="reference internal" href="B_chapter4.html">
Chapter 4. 반복문
</a>
</li>
<li class="toctree-l1">
<a class="reference internal" href="B_chapter5.html">
Chapter 5. 리스트
</a>
</li>
<li class="toctree-l1">
<a class="reference internal" href="B_chapter6.html">
Chapter 6. 함수
</a>
</li>
<li class="toctree-l1">
<a class="reference internal" href="B_chapter7.html">
Chapter 7. 딕셔너리, 튜플, 셋
</a>
</li>
</ul>
<p aria-level="2" class="caption" role="heading">
<span class="caption-text">
Web Crawing
</span>
</p>
<ul>
<li class="toctree-l1">
<a class="reference internal" href="B_chapter9.html">
Chapter 9. 웹과 웹크롤링
</a>
</li>
</ul>
<p aria-level="2" class="caption" role="heading">
<span class="caption-text">
Data Science
</span>
</p>
</div>
</div>
</body>
</html>
태그 이동#
가져온 웹페이지에서 원하는 데이터를 추출하기 위해서는 데이터에 접근부터 해야한다.
먼저 데이터가 있는 태그까지 접근하는 방법을 알아보자.
BeautifulSoup은 객체(soup)에 점(.)을 붙여서 태그간 이동을 지원한다. 즉 점을 통해 원하는 태그에 접근할 수 있다.
변수 soup의 현재 위치는 태그의 가장 바깥쪽인
<html>태그에 위치하고 있고, 구조상<html>다음 태그로는<head>태그와<body>가 있다.이 가운데
<body>태그로 이동하려면 soup.body와 같이 쓴다.<body>태그로 이동하면<body>태그가 가장 바깥쪽 태그로 보여진다.
print(soup.body)
<body>
<div class="tex2jax_ignore mathjax_ignore section" id="id1">
<h1>소개<a class="headerlink" href="#id1" title="Permalink to this headline">#</a></h1>
<p>L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅</p>
<p>프로그래밍 입문자와 비전공자를 위한 파이썬 프로그래밍 기초와 데이터 과학 기초를 다룬다.</p>
<p>컴퓨팅 기초: 처음 만나는 컴퓨팅 001,002,003 강좌 수강생들을 위한 자료이니 복제, 무단배포, 링크공유를 금합니다.</p>
<div class="toctree-wrapper compound">
<p aria-level="2" class="caption" role="heading"><span class="caption-text">Python</span></p>
<ul>
<li class="toctree-l1"><a class="reference internal" href="B_chapter0.html">Chapter 0. 프로그래밍 언어와 파이썬</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter1.html">Chapter 1. 기본자료형과 변수</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter2.html">Chapter 2. 입출력과 타입변환</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter3.html">Chapter 3. 조건문</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter4.html">Chapter 4. 반복문</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter5.html">Chapter 5. 리스트</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter6.html">Chapter 6. 함수</a></li>
<li class="toctree-l1"><a class="reference internal" href="B_chapter7.html">Chapter 7. 딕셔너리, 튜플, 셋</a></li>
</ul>
<p aria-level="2" class="caption" role="heading"><span class="caption-text">Web Crawing</span></p>
<ul>
<li class="toctree-l1"><a class="reference internal" href="B_chapter9.html">Chapter 9. 웹과 웹크롤링</a></li>
</ul>
<p aria-level="2" class="caption" role="heading"><span class="caption-text">Data Science</span></p>
</div>
</div>
</body>
점(.)을 통한 태그 접근은 반드시 태그 순서대로 해야 하는 것은 아니다.
<body><div><p>태그가 차례대로 있는데 이 중<p>태그에 접근하려면 soup.p로 쓰면 soup의 현재 위치인 가장 바깥쪽인 태그에서 아래쪽으로 가장 가까운<p>태그로 이동한다.
soup.p
<p>L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅</p>
그렇다면 다음
<p>태그에 접근하려면 어떻게 해야 할까?어느 태그의 동일 레벨 즉, 형제 태그에 접근하려면 next_sibling과 previous_sibling을 사용하면 된다.
같은 부모 태그를 갖는 태그들을 형제(sibling)라고 하는데, 예를 들어,
<p class="inner-text first-item" ...>태그와,<p class="inner-text second-item">는 형제 태그이다.그런데 이 두 태그만 형제인 것이 아니다. 사실
<p>태그와<p>태그 사이에는 줄바꿈 기호(‘\n’)가 들어가 있다. 즉, 줄바꿈 기호도 이들의 형제이다.이 셋의 부모 태그는
<div>태그이다.
soup.p.next_sibling
'\n'
soup.p.next_sibling.next_sibling
<p>프로그래밍 입문자와 비전공자를 위한 파이썬 프로그래밍 기초와 데이터 과학 기초를 다룬다.</p>
soup.a
<a class="headerlink" href="#id1" title="Permalink to this headline">#</a>
텍스트 추출하기#
추출하려는 데이터가 있는 태그까지 접근했다면 텍스트를 추출해보자.
텍스트를 추출하는 방법은 다음과 같다.
get_text(): 현재 태그를 포함하여 모든 하위 태그에 있는 텍스트를 추출한다.
괄호안에 별도의 옵션을 줄 수 있다. 예) strip=True
text: 현재 태그를 포함하여 모든 하위 태그에 있는 텍스트를 추출한다.
.string: 태그에 컨텐츠가 하나인 경우만 추출가능하다.
get_text()와 text는 정확히 동일한 결과를 반환한다. 차이점이 있다면 get_text()의 경우 괄호안에 별도의 옵션을 줄 수 있다는 것이다. 예) get_text(strip=True)
print(soup.get_text())
Very Simple HTML Code by Haesun
소개#
L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅
프로그래밍 입문자와 비전공자를 위한 파이썬 프로그래밍 기초와 데이터 과학 기초를 다룬다.
컴퓨팅 기초: 처음 만나는 컴퓨팅 001,002,003 강좌 수강생들을 위한 자료이니 복제, 무단배포, 링크공유를 금합니다.
Python
Chapter 0. 프로그래밍 언어와 파이썬
Chapter 1. 기본자료형과 변수
Chapter 2. 입출력과 타입변환
Chapter 3. 조건문
Chapter 4. 반복문
Chapter 5. 리스트
Chapter 6. 함수
Chapter 7. 딕셔너리, 튜플, 셋
Web Crawing
Chapter 9. 웹과 웹크롤링
Data Science
print(soup.text)
Very Simple HTML Code by Haesun
소개#
L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅
프로그래밍 입문자와 비전공자를 위한 파이썬 프로그래밍 기초와 데이터 과학 기초를 다룬다.
컴퓨팅 기초: 처음 만나는 컴퓨팅 001,002,003 강좌 수강생들을 위한 자료이니 복제, 무단배포, 링크공유를 금합니다.
Python
Chapter 0. 프로그래밍 언어와 파이썬
Chapter 1. 기본자료형과 변수
Chapter 2. 입출력과 타입변환
Chapter 3. 조건문
Chapter 4. 반복문
Chapter 5. 리스트
Chapter 6. 함수
Chapter 7. 딕셔너리, 튜플, 셋
Web Crawing
Chapter 9. 웹과 웹크롤링
Data Science
문자열 앞뒤의 여백(whitespace)를 지울 때에는 strip() 메서드를 사용하면 된다. 여기서 문자열의 기준은 soup위치 기준이다.
print(soup.text.strip())
Very Simple HTML Code by Haesun
소개#
L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅
프로그래밍 입문자와 비전공자를 위한 파이썬 프로그래밍 기초와 데이터 과학 기초를 다룬다.
컴퓨팅 기초: 처음 만나는 컴퓨팅 001,002,003 강좌 수강생들을 위한 자료이니 복제, 무단배포, 링크공유를 금합니다.
Python
Chapter 0. 프로그래밍 언어와 파이썬
Chapter 1. 기본자료형과 변수
Chapter 2. 입출력과 타입변환
Chapter 3. 조건문
Chapter 4. 반복문
Chapter 5. 리스트
Chapter 6. 함수
Chapter 7. 딕셔너리, 튜플, 셋
Web Crawing
Chapter 9. 웹과 웹크롤링
Data Science
soup.a 태그에는 컨텐츠가 하나이므로 .string으로 문자열 추출이 가능하다.
print(soup.a.string)
#
그러나 .string 추출하려는 태그 안에 컨텐츠가 여러 개이면 추출할 수 없다.
예를 들어, soup에는 하위태그도 많은데다가 각 하위태그마다 컨텐츠가 있어서, 컨텐츠가 여러개 이므로 .string으로는 추출할 수 없다.
soup.string
개발자 도구 활용하기#
HTML 문서는 매우 길고 많은 태그들이 중첩되어 있어서 구조를 파악하기가 쉽지 않다. 구조 파악이 어렵기 때문에 점(.)을 통한 이동으로 데이터를 추출하기가 매우 어렵다.
이를 위해 웹페이지의 구조를 파악하기 쉽도록 구조를 보여주는 도구가 바로
개발자 도구이다.개발자 도구를 활용하면 추출하고자 하는 데이터가 어느 태그에 혹은 어떤 속성을 갖고 있는지 쉽게 확인할 수 있다.
개발자 도구는 브라우저에서 일반적으로
오른쪽 상단에 (...)를 클릭하여 도구 더보기 > 개발자 도구를 클릭하면 보인다.단축키는 F12 또는 Ctrl+Shift+I이다.
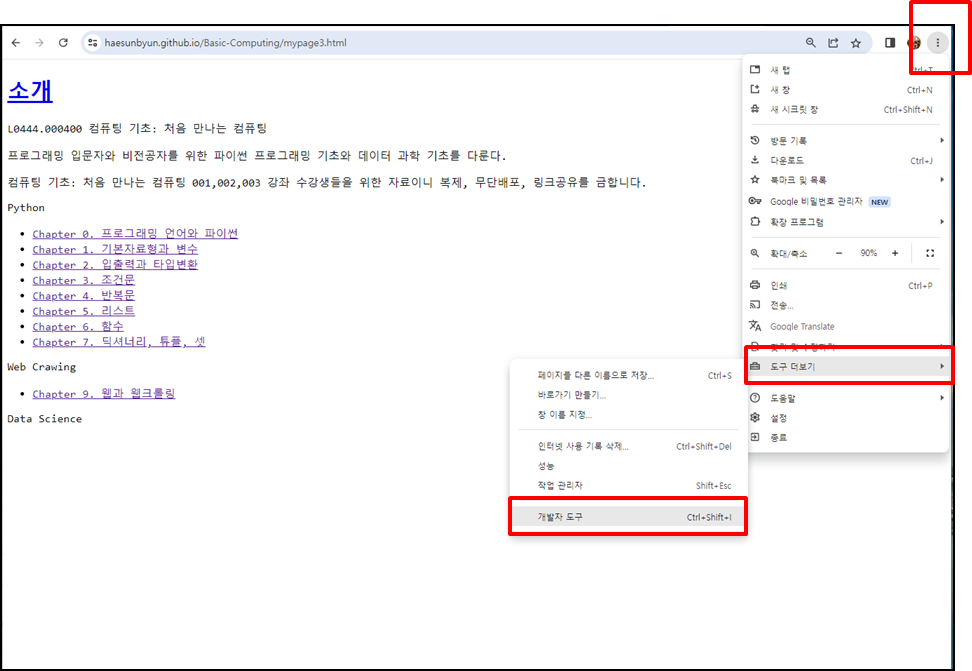
개발자 도구로 들어가면 왼쪽에 창이 열리면서 웹페이지의 소스코드를 구조적으로 볼 수 있다.
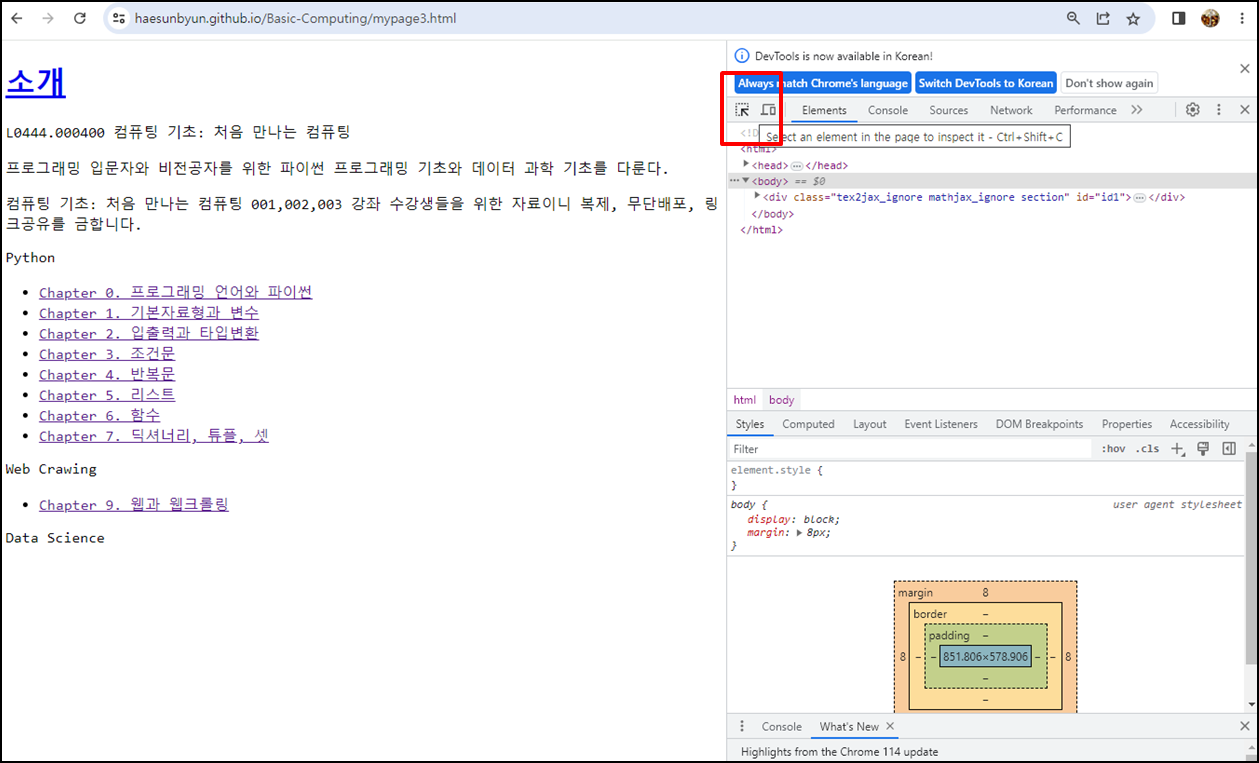
소스코드 창 왼쪽 상단에 화살표 모양의 요소(element) 선택 버튼을 클릭한다.
요소 선택 버튼은 현재 로딩된 웹페이지의 컨텐츠로 마우스를 가져가면 해당 요소의 상세 정보(태그 정보, CSS 정보)와 소스보기의 해당 요소 위치로 바로 이동시켜주는 기능을 제공한다.마우스를 이동시킬 때마다 소스보기에서도 음영처리된 부분이 바뀌는 것을 볼 수 있을 것이다.
태그로 찾기#
BeautifulSoup의 태그나 속성으로 찾을 수 있도록 하는 find()와 find_all() 메서드를 지원한다.
soup.find('tag명'): 가장 처음에 있는 <tag명> 하나만 반환
soup.find_all('tag명'): <tag명>을 모두 찾아내어 리스트와 비슷한 형태로 반환.
먼저, find() 메서드를 사용해보자.
추출하려는 데이터가 “L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅”이라고 해보자.
추출하려는 데이터가 어떤 태그에 있는지 혹은 어떤 속성을 갖고 있는지 개발자 도구를 통해 확인한다.
확인을 했다면, 다시 코드로 와서 find()나 find_all()을 이용해 찾는다.
soup.find('p')
<p>L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅</p>
검색된
<p>태그에서 문자열을 추출한다.
soup.find('p').text
'L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅'
이번에는 find_all() 메서드로 모든
<p>태그를 찾아보자.
ptagList = soup.find_all('p')
print(ptagList)
[<p>L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅</p>, <p>프로그래밍 입문자와 비전공자를 위한 파이썬 프로그래밍 기초와 데이터 과학 기초를 다룬다.</p>, <p>컴퓨팅 기초: 처음 만나는 컴퓨팅 001,002,003 강좌 수강생들을 위한 자료이니 복제, 무단배포, 링크공유를 금합니다.</p>, <p aria-level="2" class="caption" role="heading"><span class="caption-text">Python</span></p>, <p aria-level="2" class="caption" role="heading"><span class="caption-text">Web Crawing</span></p>, <p aria-level="2" class="caption" role="heading"><span class="caption-text">Data Science</span></p>]
find_all()의 결과는 ‘bs4.element.ResultSet’이다. 리스트는 아니지만 리스트처럼 보여지며, 리스트와 같이 접근이 가능하다.
print(type(ptagList))
ptagList[0]
<class 'bs4.element.ResultSet'>
<p>L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅</p>
또한 문자열 추출도 가능하다.
ptagList[0].text
'L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅'
‘bs4.element.ResultSet’은 반복가능한 데이터셋이다.
즉, 리스트처럼 반복문에서 활용할 수 있다.
for each in soup.find_all('p'):
print(each.text)
L0444.000400 컴퓨팅 기초: 처음 만나는 컴퓨팅
프로그래밍 입문자와 비전공자를 위한 파이썬 프로그래밍 기초와 데이터 과학 기초를 다룬다.
컴퓨팅 기초: 처음 만나는 컴퓨팅 001,002,003 강좌 수강생들을 위한 자료이니 복제, 무단배포, 링크공유를 금합니다.
Python
Web Crawing
Data Science
for each in soup.find_all('a'):
print(each.string)
#
Chapter 0. 프로그래밍 언어와 파이썬
Chapter 1. 기본자료형과 변수
Chapter 2. 입출력과 타입변환
Chapter 3. 조건문
Chapter 4. 반복문
Chapter 5. 리스트
Chapter 6. 함수
Chapter 7. 딕셔너리, 튜플, 셋
Chapter 9. 웹과 웹크롤링
속성으로 찾기#
find()나 find_all()함수에서 전달인자로 태그 안에 있는 속성명이나 속성값을 함께 지정하여 찾을 수도 있다.
조건을 여러개 지정하면 찾고자 하는 데이터에 더 근접하여 추출할 수 있다.
조건을 속성명만 줄 때에는 태그명을 생략할 수도 있다.
soup.find('tag명', 속성명='속성값')
soup.find_all(속성명='속성값')
예를들어, 태그가
<p>이면서 class가 ‘caption’인 것을 모두 찾는다면 아래와 같이 쓸 수 있다.이때 주의해야 할 것은 class라는 속성명은 반드시 class_로 써야 한다.
soup.find_all('p', class_='caption')
[<p aria-level="2" class="caption" role="heading"><span class="caption-text">Python</span></p>,
<p aria-level="2" class="caption" role="heading"><span class="caption-text">Web Crawing</span></p>,
<p aria-level="2" class="caption" role="heading"><span class="caption-text">Data Science</span></p>]
속성명 class가 ‘toctree-l1’인 것을 모두 찾아서 내용만 출력한다.
for each in soup.find_all(class_='toctree-l1'):
print(each.text)
Chapter 0. 프로그래밍 언어와 파이썬
Chapter 1. 기본자료형과 변수
Chapter 2. 입출력과 타입변환
Chapter 3. 조건문
Chapter 4. 반복문
Chapter 5. 리스트
Chapter 6. 함수
Chapter 7. 딕셔너리, 튜플, 셋
Chapter 9. 웹과 웹크롤링
속성값 추출하기#
어떤 경우에는 속성값을 추출해야 할 필요가 있기도 하다. 대표적인 예로 링크주소를 추출하고 싶을 때가 그렇다.
이럴 때에는 속성명을 활용하여 속성값을 추출하면 된다.
속성값을 추출할 때에는 태그 뒤 대괄호[ ] 안에 속성명을 문자열로 넣어주면 된다.
soup.find('p')['속성명']
태그로 직접 접근해 속성값을 추출할 수 있다.
soup.a['href']
'#id1'
find() 메서드로 찾아 속성값을 추출할 수 있다.
soup.find('a')['href']
'#id1'
find_all() 메서드로 찾아 속성값을 추출할 수 있다.
for each in soup.find_all('a'):
print(each['href'])
#id1
B_chapter0.html
B_chapter1.html
B_chapter2.html
B_chapter3.html
B_chapter4.html
B_chapter5.html
B_chapter6.html
B_chapter7.html
B_chapter9.html
for each in soup.find_all('a'):
print(f"{each['href']} : {each.string}")
#id1 : #
B_chapter0.html : Chapter 0. 프로그래밍 언어와 파이썬
B_chapter1.html : Chapter 1. 기본자료형과 변수
B_chapter2.html : Chapter 2. 입출력과 타입변환
B_chapter3.html : Chapter 3. 조건문
B_chapter4.html : Chapter 4. 반복문
B_chapter5.html : Chapter 5. 리스트
B_chapter6.html : Chapter 6. 함수
B_chapter7.html : Chapter 7. 딕셔너리, 튜플, 셋
B_chapter9.html : Chapter 9. 웹과 웹크롤링
마무리#
웹페이지를 만드는데 사용되는 언어중 하나가 바로 HTML이다.
HTML은 태그와 내용으로 구성되어 있다.
웹페이지 크롤링은 urllib.request 모듈의 urlopen() 함수를 통해 할 수 있다
BeautifulSoup() 함수는 HTML에서 데이터를 추출할 수 있도록 하는 함수로 HTML 구문 분석 기능을 갖고 있다.
html에서 태그 찾기는
soup.find(‘tag명’): 첫 <tag명>을 찾아 반환
soup.find_all(‘tag명’): <tag명>을 모두 찾아 묶음으로 반환
속성명 = ‘속성값’을 괄호안에 추가로 넣어서 찾을 수 있다.
태그에서 데이터 추출하기는
속성값 추출하기: [‘속성명’] 활용
tag의 Text 추출하기: get_text(), text, string 등으로 추출할 수 있다.
웹페이지의 구조를 파악하기 쉽도록 구조를 보여주는 도구가 바로 개발자 도구이다.
개발자 도구를 활용하여 추출하고자 하는 데이터의 태그명과 속성을 보다 쉽게 확인할 수 있다.