Chapter 9-2. 동적 웹크롤링#
학습목표와 기대효과
학습목표
셀레니움(selenium) 모듈에 대해서 알아보자.
웹드라이버를 활용하여 자바스크립트가 적용된 웹페이지를 스크랩핑 해보자.
셀레니움에서 지원하는 중요한 메서드들을 알아보자.
기대효과
로그인이 필요하거나, 클릭이 필요한 웹페이지에서 데이터를 추출할 수 있다.
셀레니움이란?#
요즘 대부분의 웹페이지는 HTML안에 자바스크립트가 들어가 있어서 동적으로 사용자와 소통한다. 즉, 웹페이지가 사용자의 키보드 입력, 사용자의 마우스 클릭에 동적으로 반응한다는 의미이다.
이와 같이 자바스크립트를 활용한 웹 페이지를 스크랩핑 하려면 자바스크립트를 해석할 수 있는 크롤러가 필요하다.
셀레니움은 자바스크립트가 적용된 웹페이지에서 스크랩핑을 지원하는 모듈로 웹드라이버 기능을 활용하여 다양한 웹브라우저를 자동으로 조작한다.
설치 및 환경설정#
환경설정#
2023년 1월 초까지만 해도 아래와 같은 코드없이 코랩에서 크롬브라우저와 셀레니움이 단 몇줄의 코드로 잘 설치되었다.
그러나 1월 중순부터 우분투(Linux 배포판중에 하나) 운영체제를 사용하고 있는 코랩에서 크롬브라우저 배포를 더 이상 지원하지 않은 관계로 아래와 같은 복잡한 환경 설정이 필요하게 되었다.
이 코드는 크롬브라우저와 셀레니움 설치하고 동작시키기 위한 환경설정 코드이다.
한줄 한줄 의미가 무엇인지 알지 못해도 상관없다. 그냥 실행시키면 된다.
%%shell
# Ubuntu no longer distributes chromium-browser outside of snap
#
# Proposed solution: https://askubuntu.com/questions/1204571/how-to-install-chromium-without-snap
# Add debian buster
cat > /etc/apt/sources.list.d/debian.list <<'EOF'
deb [arch=amd64 signed-by=/usr/share/keyrings/debian-buster.gpg] http://deb.debian.org/debian buster main
deb [arch=amd64 signed-by=/usr/share/keyrings/debian-buster-updates.gpg] http://deb.debian.org/debian buster-updates main
deb [arch=amd64 signed-by=/usr/share/keyrings/debian-security-buster.gpg] http://deb.debian.org/debian-security buster/updates main
EOF
# Add keys
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys DCC9EFBF77E11517
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 648ACFD622F3D138
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 112695A0E562B32A
apt-key export 77E11517 | gpg --dearmour -o /usr/share/keyrings/debian-buster.gpg
apt-key export 22F3D138 | gpg --dearmour -o /usr/share/keyrings/debian-buster-updates.gpg
apt-key export E562B32A | gpg --dearmour -o /usr/share/keyrings/debian-security-buster.gpg
# Prefer debian repo for chromium* packages only
# Note the double-blank lines between entries
cat > /etc/apt/preferences.d/chromium.pref << 'EOF'
Package: *
Pin: release a=eoan
Pin-Priority: 500
Package: *
Pin: origin "deb.debian.org"
Pin-Priority: 300
Package: chromium*
Pin: origin "deb.debian.org"
Pin-Priority: 700
EOF
UsageError: Cell magic `%%shell` not found.
웹브라우저 한글폰트 깨짐 방지#
코랩에서 웹브라우저를 구동시켜 웹페이지에 접속했을 때 한글 폰트가 깨져서 네모로 나오는 것을 방지한다.
!apt-get install fonts-unfonts-core
크롬드라이버 설치#
코랩에서 크롬드라이버(웹드라이버)를 동작시키기 위해 크롬 드라이버를 설치한다.
!apt-get update
!apt-get install chromium chromium-driver
!apt-get update
!apt-get install chromium chromium-driver
크롬드라이버 구동#
설치가 성공적으로 완료되었다면 크롬 드라이버의 옵션 몇 가지를 설정해줘야 한다.
options.add_argument("--headless")는 코랩에서는 윈도우 탭을 열 수 없으므로 윈도우 탭을 생성하지 않겠다는 옵션이다.options.add_argument("--no-sandbox")는 보안기능을 비활성화하는 옵션이다. 일부 사이트에 접근할 때 웹브라우저에 보안기능이 적용되서 팝업을 차단시킨다거나, 웹사이트 접근을 차단하는 등의 기능이 적용되기도 한다. 이러한 기능이 적용되면 웹페이지에 접속할 수 없으므로 이 기능을 비활성화 시킨다.웹드라이버(크롬브라우저)를 구동시켜서 변수 driver에 저장한다.
driver = webdriver.Chrome(options=options)
여기까지 진행하면 실제 브라우저가 구동되는 것이 보이지는 않지만 내부적으로 브라우저가 구동된다.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
driver = webdriver.Chrome(options=options)
네이버 접속#
#1. 네이버 접속하여 검색하기#
이제 웹드라이버를 통해 네이버에 접속해보자.
웹페이지에 접속할 때에는 driver.get() 함수를 사용한다.
driver.get(url)
웹페이지에 접속은 네트워크 상황에 따라 몇 초정도 소요될 수도 있다. 따라서 로딩되는 시간을 기다려야 한다.
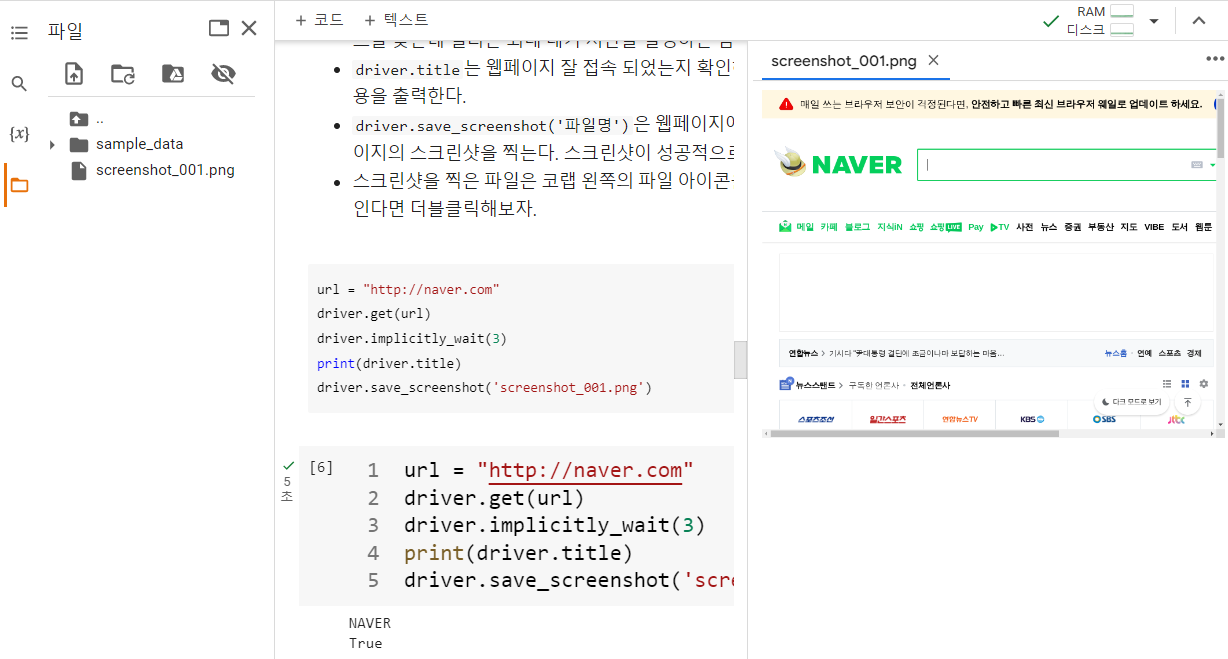
driver.implicitly_wait(s)은 웹드라이버에게 웹페이지가 로딩되는 시간 또는 엘리먼트를 찾는데 걸리는 최대 대기 시간을 설정하는 함수이다.driver.title는 웹페이지 잘 접속 되었는지 확인하기 위해 웹페이지의 제목표시줄의 내용을 출력한다.driver.save_screenshot('파일명')은 웹페이지에 잘 접속 되었는지 확인하기 위해 웹페이지의 스크린샷을 찍는다. 스크린샷이 성공적으로 찍히면 True를 반환한다.스크린샷을 찍은 파일은 코랩 왼쪽의 파일 아이콘을 클릭하여 확인 할 수 있다. 파일이 보인다면 더블클릭해보자.
url = "http://naver.com"
driver.get(url)
driver.implicitly_wait(3)
print(driver.title)
driver.save_screenshot('screenshot_001.png')
#2. 네이버 검색어 입력#
동적 웹페이지에서 웹크롤링을 하려면 사람이 하는 동작 그대로 코드에게 일을 시켜야 한다.
네이버 검색어 입력박스에 검색어가 입력되도록 해보자. 사람은 눈으로 보고 검색어 입력박스를 찾을 수 있지만 코드는 그렇게 하지 못한다.
따라서 검색어 입력박스의 엘리먼트(element)를 찾아서 알려줘야 한다.

개발자 도구를 활용하여 검색어 입력박스 엘리먼트의 태그와 속성을 확인한다.
검색어 입력박스의 태그와 속성은
<input id="query" name="query" ...>이다.
셀레니움에서 엘리먼트를 찾는 방법은 다음과 같다.
find_element(): 하나의 엘리먼트를 찾는다.
find_elements(): 여러개의 엘리먼트를 찾는다.
find_element(), find_elements() 함수의 괄호안에는 추출할 옵션을 넣어준다. 옵션의 종류는 다음과 같다.
By.ID 태그의 id값으로 추출
By.NAME 태그의 name값으로 추출
By.XPATH 태그의 경로로 추출
By.LINK_TEXT 링크 텍스트값으로 추출
By.PARTIAL_LINK_TEXT 링크 텍스트의 자식 텍스트 값을 추출
By.TAG_NAME 태그명으로 추출
By.CLASS_NAME 태그의 클래스명으로 추출
By.CSS_SELECTOR css선택자로 추출
위 옵션을 사용하려면 By 클래스를 먼저 import해야 한다.
from selenium.webdriver.common.by import By
검색어 입력박스 찾기와 검색어 입력#
예를 들어, 검색어 입력박스의 속성가운데 하나인 ID로 찾는다면 find_element(By.ID, “query”)로 넣어준다.
검색어 입력박스 엘리먼트를 찾았다면
엘리먼트.send_keys()괄호안에 검색어를 넣어준다.아래 코드에서는 엘리먼트를 box_elem으로 저장했으므로 box_elem.send_keys(‘공휴일’)과 같이 작성하였다.
검색박스의 문자열을 지우려면 엘리먼트.clear()하면 된다.
from selenium.webdriver.common.by import By
box_elem = driver.find_element(By.ID, "query") #검색어 입력박스
box_elem.send_keys('공휴일') #검색어 입력
#box_elem.clear()
driver.save_screenshot('screenshot_002.png')
검색버튼 클릭되게 하기#
검색어가 입력된 것을 확인했으니 검색이 이루어지도록 검색버튼이 클릭되게 해보자.
이때 버튼의 경우는 개발자도구에서 xpath를 찾아 넣어주자.
xpath는 XML Path Language로, 문서의 특정 요소나 속성에 접근하기 위한 경로이다.
개발자도구 > 엘리먼트 선택 버튼 > 네이버의 검색버튼으로 가서 클릭해보자. 오른쪽 개발자도구의 소스코드영역에 해당 검색버튼이 있는 html 코드가 있을 것이다.
그 html 코드 위에서 마우스 오른쪽 버튼을 클릭하여 copy > copy xpath를 클릭한다.
그러면 xpath 값이 클립보드에 저장된다. 이를 코랩에서 변수 xpath에 붙여넣기 하여 문자열로 저장한다.
find_element(By.XPATH, value=xpath)로 검색버튼 엘리먼트를 찾아 click()함수로 클릭되게 한다.
검색 버튼이 클릭되면 검색 결과 페이지가 나온다. 스크린샷을 찍어서 검색이 잘 되었는지 확인해보자.
이전 페이지로 이동하려면 driver.back()한다.
xpath = '여러분이 채워주세요.' #검색버튼 xpath
driver.find_element(By.XPATH, value=xpath).click()
driver.implicitly_wait(3)
driver.save_screenshot('screenshot_003.png')
#driver.back()
연습: 검색어 입력받아 검색하기#
😄 검색어를 입력받아 네이버에서 검색하도록 소스코드를 작성해보세요. 결과를 ‘screenshot_004.png’로 저장하세요.
driver.get('https://www.naver.com/')
driver.implicitly_wait(3)
#Todo
#3. 네이버 블로그에서 검색하기#
연습: 네이버 블로그 검색하기#
😄 네이버 블로그에서 ‘워터파크’을 검색하도록 코드를 작성하고 실행하여 ‘screenshot_005.png’로 저장하시오.
#4. 웹페이지 컨텐츠 추출하기#
이제 웹페이지 검색결과에서 필요한 데이터를 추출해보자.
두 가지 방법을 모두 사용해보자.
이전에 배웠던 BeautifulSoup으로 추출해 본다.
셀레니움으로 추출해본다.
BeautifulSoup으로 추출하기#
BeautifulSoup으로 추출할 때에는 먼저 검색된 웹페이지를
driver.page_source로 HTML 코드를 가져와 변수 html에 저장한다.BeautifulSoup(html, ‘html.parser’)으로 파싱한다.
추출하려고 하는 컨텐츠가 어떤 태그와 속성을 가지고 있는지 개발자 도구를 활용하여 알아낸 후, find_all()로 검색한다.
검색된 결과에서 필요한 컨텐츠만 추출한다.
from bs4 import BeautifulSoup
html=driver.page_source
soup = BeautifulSoup(html, 'html.parser')
subject_list = soup.find_all(class_="title_post")
for each in subject_list:
print(each.get_text().strip())
셀레니움으로 추출하기#
셀레니움으로 추출하면 페이지를 가져올 필요없이 바로 추출 가능하다.
단 셀리니움으로 찾은 결과는 BeautifulSoup에서와 달리 selenium.webdriver.remote.webelement.WebElement로 나온다. 아래 코드에서 print(subject_list)를 해보고 그 결과를 확인하자.
subject_list = driver.find_elements(By.CLASS_NAME, "title_post" )
for each in subject_list:
print(each.text)
#5. 페이지 이동하면서 컨텐츠 추출하기#
페이지 번호의 xpath 추출하기#
1페이지의 제목은 추출했으니 2페이지, 3페이지 이동하면서 제목을 추출해보자.
사람이 2페이지 검색결과를 보려면 페이지번호 중에 2를 클릭 할 것이다. 이를 코드가 나 대신 클릭하도록 해줘야 한다.
이를 위해 개발자 도구를 활용하여 페이지번호 2의 xpath를 추출한다.
xpath를 활용하여 그 엘리먼트가 클릭되게 한 후, 페이지가 로딩되었다면 다시 제목을 추출해보자.
xpath = '//*[@id="content"]/section/div[3]/span[2]/a'
driver.find_element(By.XPATH, value=xpath).click()
driver.implicitly_wait(10)
subject_list = driver.find_elements(By.CLASS_NAME, "title_post" )
for each in subject_list:
print(each.text)
반복적으로 일시키기#
개발자 도구를 활용하여 페이지번호 2, 페이지번호 3, 페이지번호 4 등의 xpath를 확인해 보고 어느 부분이 바뀌고 있는지 체크하자.
xpath의 값이 거의 비슷한데 span[2], span[3], span[4]와 같이 페이지번호에 따라 span[] 대괄호안의 숫자만 달라지고 있다.
반복문으로 실행시키기 딱 좋은 구조이다. 2, 3, 4라는 상수값을 변수로 줘서 반복문으로 실행시킬 수 있다.
1페이지부터 5페이지까지 제목만 추출해서 리스트로 만들어보자.
import time
titleList=[]
for i in range(1,6):
xpath = f'//*[@id="content"]/section/div[3]/span[{i}]/a'
driver.find_element(by=By.XPATH, value=xpath).click()
time.sleep(3)
subject_list = driver.find_elements(By.CLASS_NAME, "title_post" )
for each in subject_list:
titleList.append(each.text.strip())
print(f'-------{i}/5')
print(titleList)
#6. 속성값 추출하기#
블로그에서 검색어에 대한 제목뿐만 아니라 블로그 링크까지 추출해보자.
셀레니움으로 속성값을 추출할 때에는 get_attribute() 메서드의 괄호안에 속성명을 넣어준다.
블로그 링크의 주소는 일반적으로
<a>태그에 있으나<a>태그를 가진 엘리먼트를 검색하면 대상으로 하지 않은 불필요한<a>태그까지 모두 검색된다.따라서 검색 조건을 좀 더 명확하게 주자.
<a>태그에 보니 class= ‘desc_inner’이다.링크의 주소가 들어있는 속성명을 확인해보니
ng-href이다.
a_tag_list = driver.find_elements(By.CLASS_NAME, 'desc_inner')
a_tag_list[0].get_attribute('ng-href')
반복문으로 제목과 링크를 모두 리스트로 만들어보자.
import time
titleList = []
titleLinkList = []
for i in range(1,6):
xpath = f'//*[@id="content"]/section/div[3]/span[{i}]/a'
driver.find_element(by=By.XPATH, value=xpath).click()
time.sleep(3)
subject_list = driver.find_elements(By.CLASS_NAME, "title_post" )
a_tag_list = driver.find_elements(By.CLASS_NAME, 'desc_inner')
for sub, link in zip(subject_list, a_tag_list):
titleList.append(sub.text.strip())
titleLinkList.append(link.get_attribute('ng-href'))
print(f'-------{i}/5')
print(titleList)
print(titleLinkList)
implicitly_wait() vs. time.sleep()
implicitly_wait(s)은 웹드라이버에게 최대 s초 동안 대기하도록 하는 메서드로 웹페이지가 로딩되는 시간 또는 엘리먼트를 찾는데 걸리는 최대 대기 시간을 설정하는 메서드이다. s초가 지나도 작업을 완료하지 못하면 NoSuchElementException 에러를 발생시킨다. 즉, 웹페이지가 준비도 안되었는데 엘리먼트를 찾으라 하면 NoSuchElementException 에러가 발생한다.
time.sleep(s)은 time 모듈에 포함된 함수로 실행을 s초 동안 일시 중지하였다가 시간이 경과하면 실행이 계속된다. time.sleep(s)을 웹페이지가 로딩되는 시간을 기다리는데 유용하게 사용할 수 있다. 이 경우, time.sleep(5)를 호출하면 프로그램 실행이 5초 동안 일시 중지된다. 이는 페이지 로드를 기다리거나, 웹 페이지의 스크립트가 실행되고 결과를 가져오는 데 시간이 필요한 경우 유용하게 사용된다.
이 두 코드는 서로 목적이 다르지만, 웹 스크래핑 작업에서 적절한 시점에 기다리는 용도로 사용할 수 있다.
#7. 제어 종료#
driver.close()를 통해 웹드라이버를 제어 종료한다.
마무리#
셀레니움은 사용자와 상호 인터렉션을 하는 동적 웹페이지에서 데이터를 추출하기 위한 라이브러리이다.
셀레니움을 통해 웹브라우저를 구동시켜 웹페이지 접속하려면
driver.get('웹페이지주소')
접속 중인 페이지의 HTML 소스코드를 가져오려면
html = driver.page_source
find_element(), find_elements()는 웹페이지에서 엘리먼트를 찾을 때 사용한다. 괄호안에 들어갈 옵션의 종류는 다음과 같다.
아래 옵션을 사용하려면 By 클래스를 먼저 import해야 한다.
from selenium.webdriver.common.by import By
By.ID 태그의 id값으로 추출
By.NAME 태그의 name값으로 추출
By.XPATH 태그의 경로로 추출
By.LINK_TEXT 링크 텍스트값으로 추출
By.PARTIAL_LINK_TEXT 링크 텍스트의 자식 텍스트 값을 추출
By.TAG_NAME 태그 이름으로 추출
By.CLASS_NAME 태그의 클래스명으로 추출
By.CSS_SELECTOR css선택자로 추출
버튼처럼 클릭하는 부분의 엘리먼트는 Xpath를 활용한다. xpath는 XML Path Language로, 문서의 특정 요소나 속성에 접근하기 위한 경로로 개발자 도구에서 Copy – Copy Xpath를 이용하여 Xpath를 얻어올 수 있다.
입력박스에 텍스트를 입력할 때에는
text입력: element.send_keys('입력할text')
엘리먼트를 클릭되게 하려면
element.click()
제어 종료는 driver.close()이다.